
No Code, Clean Performance
In "Clean" Code, Horrible Performance, Casey Muratori (optimization guru) argues that easily readable code with higher-level patterns (clean code) is extremely inefficient... In Horrible Code, Clean Performance, Ivica Bogosavljević (also optimization professional) argues that readability and maintainability of fast code is lost when helping compiler produce better code, as exemplified by string-searching algorithm. Both views are correct – it's a balancing act.
I was curious how baby AGI (GPT-4) would do on this task. So I, a puny copy-paster without C++ knowledge & lazy QA tester, mediated necessary actions to enable GPT-4 to solve this task. GPT-4 rewrote original example and significantly improved its performance, while made it way uglier (& slightly wrong). Is source-to-source optimizing compiler powered by GPT-4 the worst idea ever?
⚠️ No humans were harmed by reading or writing C++ code to produce this essay. All GPT4-generated code is without any guarantees! Similarly, all human-generated code is without any guarantees!
The Debate
From my point of view, the performance vs. readability debate is pointless. Of course we want easily maintainable and readable code in order to easily fix bugs and add new features. Of course we want our software to run at the highest speed possible, so we don't wait for it, so it uses less energy, and produces less heat. We want both things. Have the cake and it it too. Can we achieve it with GPT-4 as an optimizing compiler?
Substring Problem
Let's say we have a long string of mRNA bases (adenine A, cytosine C, guanine G and uracil U). And inside this letter soup (e.g. CAGCAGUAUGCGUGGAGAUCUGACUC) we want to find the first occurence of the UGG which is a code for tryptophan amino acid. Tryptophan is precursor to the neurotransmitter serotonin, the hormone melatonin, and vitamin B3. Tryptophan plays an important role in human body, so we would like to find it in the looong mRNA sequence as fast as possible. Look, here it is – CAGCAGUAUGCGUGGAGAUCUGACUC!
Benchmark
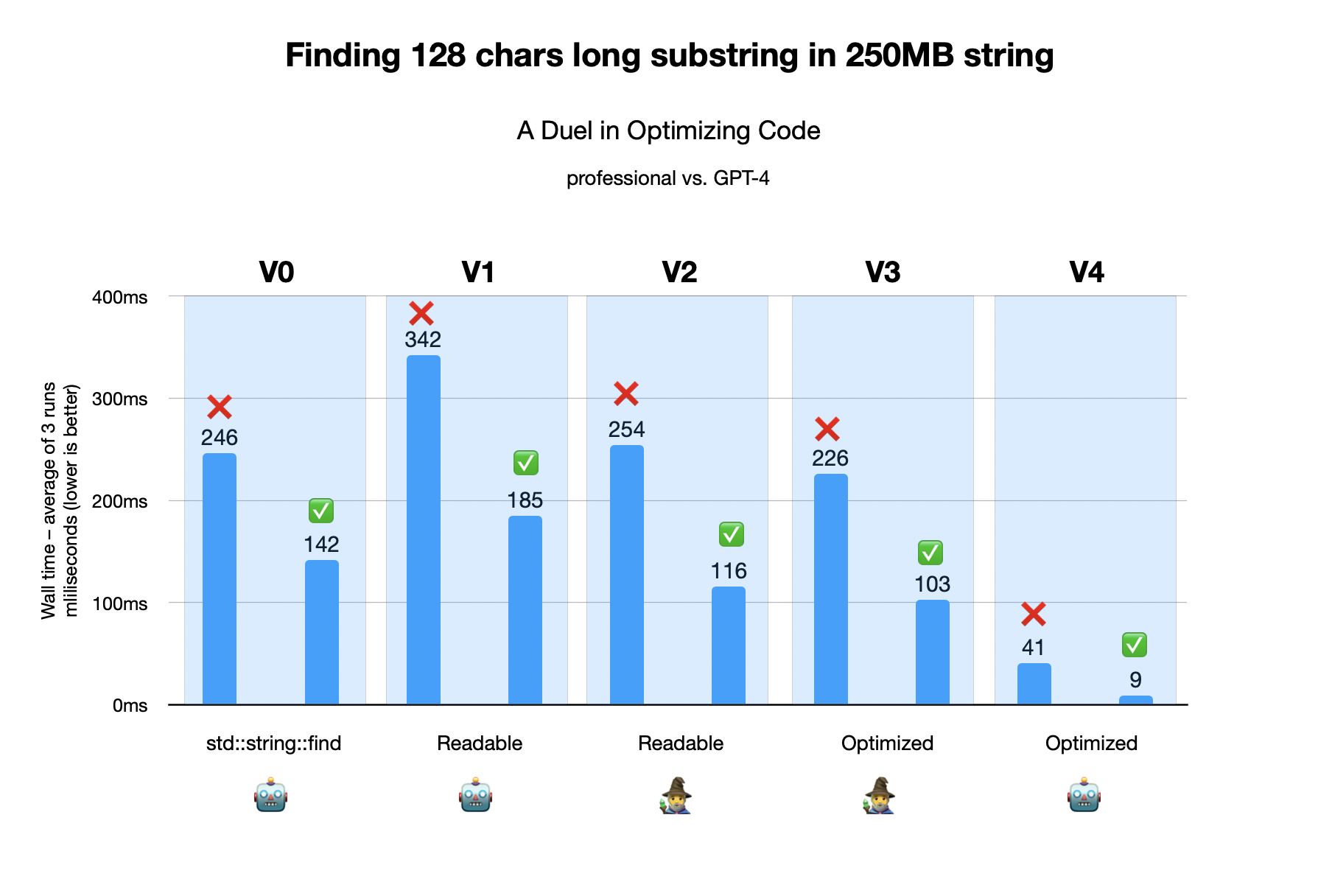
We are going to test various versions of algorithm for finding substring (128 chars long) in a large string (250MB). We have 2 test cases. First is a so called negative one – the string does not contain the shorter string, so the algorithm has to go through the whole long soup. Second test is a positive – substring is roughly in the middle of the larger string. We run both tests 3 times and report an average time.
Solutions
- Version 0 is the simplest code possible that uses library-provided
std::string::find. This is a good baseline for seeing how a lazy programmer stack against the rest of the pack. If you are a sane person, this is what you would use. Written by GPT-4. - Version 1 is what you would probably write if you would embark on an optimization journey. Always start with clean code and make it faster (& uglier) along the way. It uses
std::string. Written by GPT-4. - Version 2 is what an optimization professional wrote. It uses
my_stringstruct that contains string data and string size. (Borrowed from Ivica Bogosavljević.) - Version 3 is an optimized version by the optimization professional. The code is obviously less readable and maintainable, and marginally faster. (Borrowed from Ivica Bogosavljević.)
- Version 4 is optimized version by GPT-4. It is drasticaly preferring performance over readability. No sentient being should ever see or be forced to maintain this piece of code. Only if they are willingly into that.
Workflow
GPT-4 and other language models (humans included) work best when they can think step-by-step. This is known as chain-of-thought reasoning. So I asked GPT-4 to think in steps and add optimization one by one with clear explanation of what it is actually doing. The steps were:
- Using memcmp for substring comparison
- Using a sentinel for loop termination
- Utilizing a "bad character" heuristic
- Combining sentinel and "bad character" heuristic
The result wasn't perfect on the first try – it produced SIGSEGV. But GPT-4 is pretty good at debugging when you provide necessary information. This is how I got to V4.
I asked for additional optimization techniques, and it went onto implementing 'a variant of the Boyer-Moore-Horspool algorithm with the "good suffix" heuristic, using a simplified version of the algorithm that is easier to implement but still provides substantial performance improvements', but I didn't pursue this path.
Just to reiterate – no human wrote any C++ during this experiment – no code, clean performance.
Conclusion
I despise C++, I don't write it and I never will. I won't ever optimize C++ code by hand. Humans should care about human-side of the problem. It is the computer that should care about how to achieve it in the most efficient way. Producing optimized code from human-readable code was always a job for compiler, not for human. Current compilers are marvels, but enhancing them with human reasoning, might bring us the holy grail – readable code with optimal performance. Are we there yet? No. We have no guarantees that the produced code is functionaly equivalent to the intended version. I am not able to verify it as my lack of knowledge is limiting. Could I devise a test suite that would make some guarantees? Definitely. But I would let GPT-4 do it, as I am not interested in such endevour. Can I trust it to produce corrent test suite? No. And we are back to square one.
Let's take another view. The whole process of optimizing the code took some time. And I was the bottleneck. If GPT-4 could spawn another number of GPT-4s that could do the code editing, terminal stuff, self-debugging, and data collection, it would be much faster process. Really, the effort and contribution from my part was exactly 0.0. People are already doing impressive stuff with AutoGPT, so this is definitely a fruitful space to keep an eye on. But can it help us solve the reliability problem? I think it can.
Say that I have a human professional at hand that can read the performance-optimized C++ code, and judge that it is, or isn't the equivalent of the more readable "clean" code. Let's lower our trust in this single person by understanding that occasionally s/he might have bad days, hangover, not might show up at work, do intentional mistakes for human reasons, etc. Introducing the redundancy for this optimization guru should increase our confidence in the reliability, right? Paying 2 people to do single job isn't very lucrative for companies even though the benefit is clear.
If we had 1000 people for the same job, we could be really confident that signal in the statistics is stronger than the noise. So why not increase reliability of such automated systems through redundancy of the automated parts? Yes, it will drasticaly increase the computational budget, but this technology can improve itself and make algorithms go faster, right? And occasional halucination might even produce a novel algorithm that isn't known to us. Here be dragons.
This is still a "live" essay – I fix & rephrase stuff as I go. Everything is accessible for review, criticism is welcome.
I hate reading C++ so I really haven't checked any of the produced snippets for correctness. Some people already did, and gave critique without writing any C++ code. I'll feed back this info as copy-paster to GPT-4 and instruct it to fix the mistakes.
Extremely funny thing happend during the session – GPT-4 told me that "I will get back to you as soon as I have a revised version of the code that addresses the issue." and finished the generation of the reply. The reply was short, so it wasn't cut off. I genuinely LOLed as this felt too human – I used the phrase more than once in my carrer. And since GPT-4 cannot start a conversation on its own, this was bullshit excuse. Exactly as I used it before.
Once, it produced algo that ran in
0msand was kinda proud. I smelled bullshit, and asked about it. GPT-4 apologized, fixed the mistake, and I suggested an improvement to the test suite.- Might be interesting to see pure AutoGPT solution.
- While the presented optimization is algorithmic, GPT-4 also proposed an AVX2-optimized one. I was not able to run it without crashing, so I am not publishing it. Might try it again later.