New Kind of Paper, Part Two
In first part, I introduced a New Kind of Paper, a paper with built-in computation. Aim of the project is to enhance the best medium for thinking – paper & pencil – with capabilities of a crazy advanced calculator. To put it simply, it is a calculator app designed for iPad and Pencil, and this is how it works:
The second part of the series introduces Fluent – a language that I am designing for the New Kind of Paper. Its aim is to be easy to read and write, while providing a high-level constructs that are needed to quickly solve problems that can be turned into a computation.
But let's start with a story…
Little Gauss
Carl Friedrich Gauss was a German mathematician and physicist who made significant contributions to many fields in mathematics and science. There is one anecdote that demonstrates his level of insight. The anecdote was never proven to be true, but it will serve us well.
Little Carl was unlucky – his math teacher hated his profession and gave his students rather tedious tasks so he can rest. One day, he gave his class a task to add all numbers from 1 to 100, believing it will occupy young minds for a bit. But to his surprise, little Carl quickly came up with a correct answer – 5050. If you like movie dramatizations, you can watch the following video. By the way, pay close attention to their thinking tools…
Sorry for the language.
Carl observed that if we sequentially take numbers from both ends, we get pairs that always add up to 101, e.g. 1+100, 2+99, 3+98, etc. And since we have pairs, there is half as much as all the numbers. He reduced the task of seemingly unending addition into a single multiplication – 101*50. Clever.
This experiment can be easily replicated in modern days – children with abacuses, calculators, or even computers would be slower than little Gauss with nothing but his mind. Counting beads, typing 1+2+3+4+5+… into calculator, or writing an accumulating for-loop in Python are "one number at the time" thoughts that limit us. Gauss understood that if you want speed, you have to think about groups of numbers at the time.
Tensors
Coming from any programming language, you probably know the term array as a list of some stuff, in our case, a group of numbers. However, these arrays are not very good for computation, so instead, we are going to talk about tensors. According to PyTorch and TensorFlow, two leading frameworks for machine learning, a tensor is a generalization of scalars, vectors and matrices – a group of numbers ordered in a rectangular shape of some dimension, which we will call rank. Scalar is just a single number, e.g. 23, and its rank is 0. Vector, e.g. (1,2,3), is a one-dimensional list of numbers and has rank 1. Matrix, you guessed it, has rank 2 since it is two-dimensional grid of numbers. Shape tells us how many elements are in each dimension, and yes it is also a tensor.
One extremely neat property of tensors is that they can be manipulated like scalars – e.g. you can add a number to them:
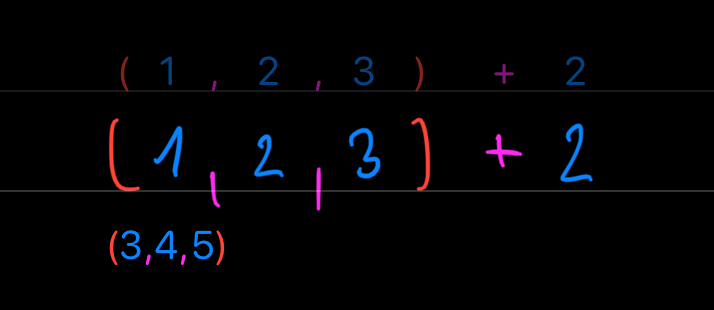
Or you can add two vectors together:
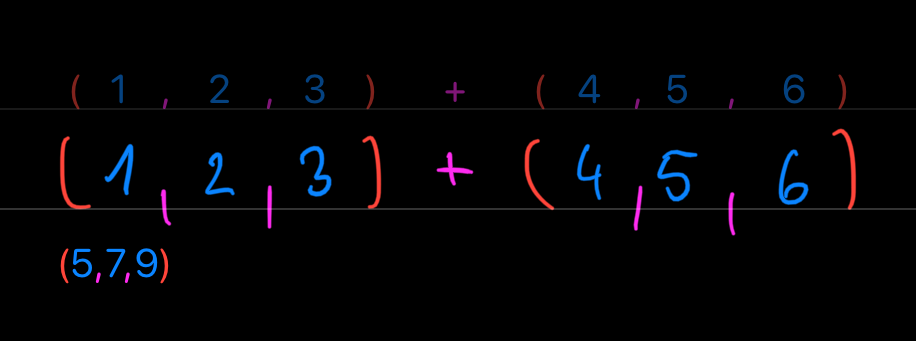
If this stinks like hidden/implicit for-loop or map operation (of the MapReduce duo), then you are right. Thinking about our Gauss story, you may be wondering: How do we add the numbers of a single vector together?
Operators
Operators such as +, -, *, / (add, subtract, multiply, divide) are extremely useful in real life, so everybody knows them. There are also other useful but less known operators like ^, <, >, = (raised to the power of, less than, greater than, equal to). Every one of these operators takes two operands, so we write them in form 1 + 2 – first operand is 1, second operand is 2 and in-between them is operator + which designates operation add. We call this form "infix notation". In this way, we are always combining two things into one, by some operation specified by the symbol.
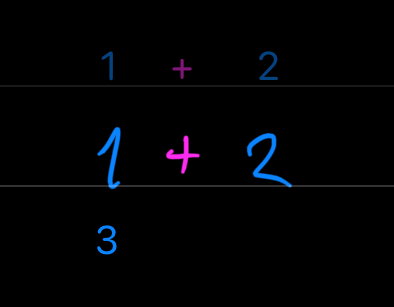
So far, all operators we mentioned combine two tensors into one. How about an operator that would take tensor and some operator as its operands? So in other words – (1,2,3) | + – we combine tensor (1,2,3) and operator + by process | (reduce). This reduce operator is a funny one.
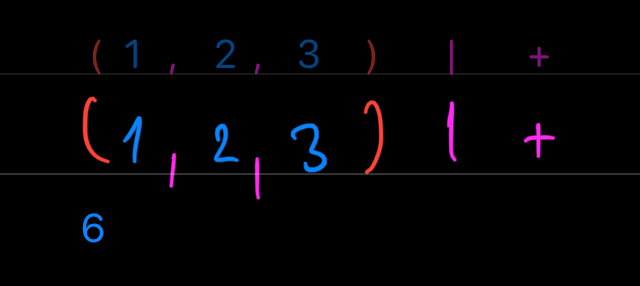
What | does is easy. If our vector is (1,2,3) then (1,2,3) | + would mean (1+2+3), i.e. reduce will insert + between the numbers of a vector. So we will get (1 + 2) + 3, which is 6. If you recognize this as ∑ (sum) then you will also know that ∏ (product) is just (1,2,3) | *.
Ok, you probably guessed that our Gauss story is simply (1,2,3, ...magic... ,98,99,100) | +. Our magic operator is called : (through) and it is used like this: 1:100 – generate vector with numbers 1 through 100.

All this combined, we now know how to encode our tedious addition problem into the compact form of 1:100 | +. Whitespace optional.
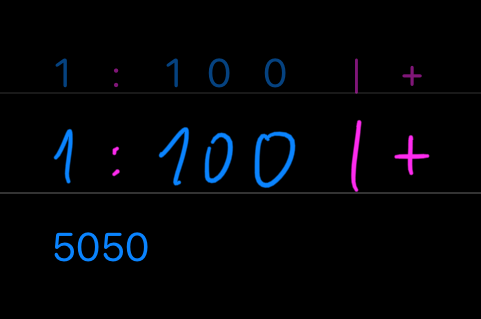
Notation as a Tool of Thought
If we align our two solutions side-by-side, we see something odd – our lazy solution is just one character longer than genius solution from Gauss:

You may rightfully object that these are equivalent only in terms of the result, i.e. running time and space complexity of those algorithms are extremely different. And you are right, but let me tell you a secret – it's not the point. The point is to quickly solve trivial tasks with little effort. Gauss didn't have a computer, we have plenty.
Another objection that may have popped into your mind is "But we had to create two new operators to make it concise!". Yes, exactly – that is the reason why we use operators – to express something in a clear and concise way. You may recognize this long expression 2 + 2 + 2 + 2 + 2 as an alternative to 2 * 5. Or 2 * 2 * 2 * 2 * 2 as 2 ^ 5. We do this all the time – we love finding shortcuts. By Marcus du Sautoy, an Oxford University professor, mathematics is the best collection of shortcuts we have, and operators are a useful way of composing well defined behaviors and get something completely new. For example, what is 2 ^ 2 ^ 2 ^ 2 ^ 2, or with the reduce operator (2,2,2,2,2) | ^ ? *
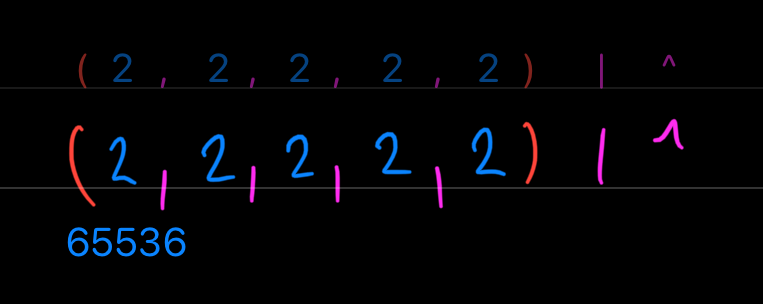
Operators are our tools for thinking. By combining them, we can encode our problems into an expression that is easy to read and write, with a side effect of irritating our math teacher. Pure win.
Fluent
Thinking by writing with a pencil, you have to use a language that is beyond what current mainstream programming languages offer. When you write Python on a whiteboard, you are missing the point, and people will make jokes about that. Having a concise notation/language makes a huge difference.
APL, but dumb and backwards
The snippets what you have seen in the context the Gauss problem are expressions in a language called Fluent. If you know some APL-style language, you probably see it as a really dumb APL. If you are coming from some C-style language, you may be a little intimidated and confused. So let me introduce Fluent by its syntax features:
- only infix binary operators
- strict left-to-right order of evaluation
- no precedence of operators
- parentheses () are the only way to change the order of evaluation (closing paren is optional)
To see how evaluation works, take a look on this simple expression – 1+2*3-4/5. Did you get 6.2? I have a bad news for you.
If you come from a tribe that uses PEMDAS (order of operations – Parentheses, Exponents, Multiplication/Division, Addition/Subtraction), your eyes were jumping left and right to evaluate that simple expression. But after some time, you proudly arrived at 6.2.
However, if you punch 1+2*3-4/5 into a common calculator, you will get different result – 1. There is a huge problem with PEMDAS – general population does not care, and coders do not remember operator precedence tables at all. So let's use something that is easier for our minds.
Expressions in Fluent are evaluated left-to-right, in other words it acts as a plain stupid calculator. So these are the same:
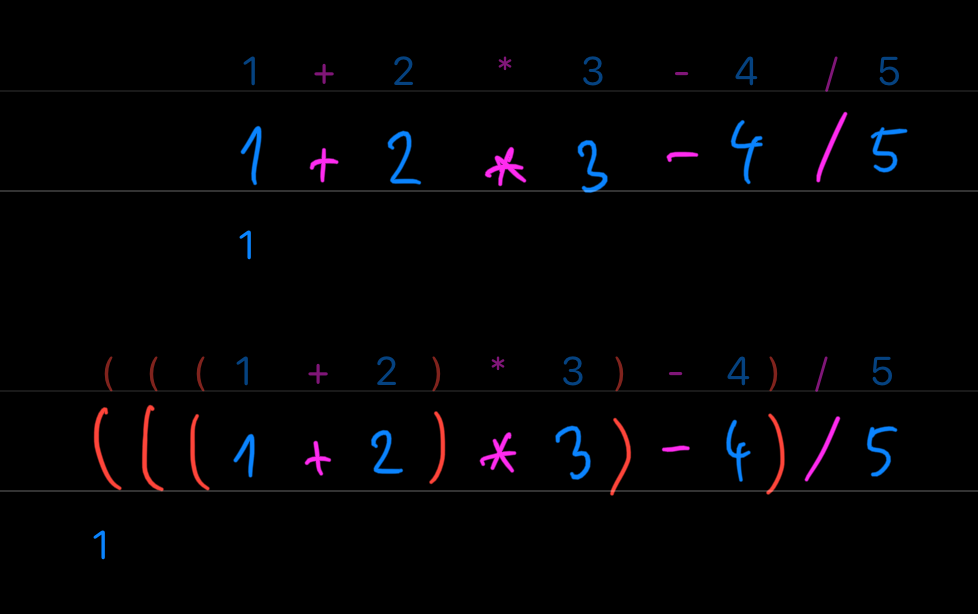
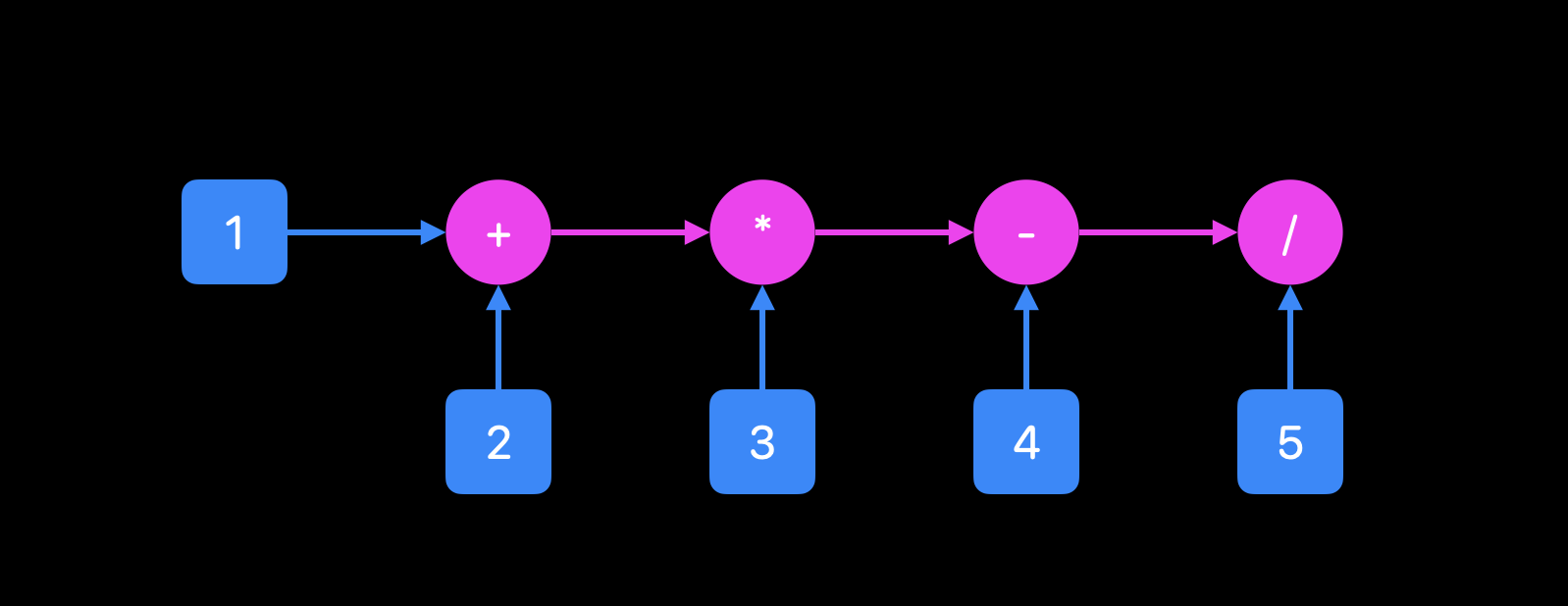
In Fluent, everything flows from left-to-right. This writing style is sometimes called pipeline or fluent interface, hence the name Fluent. So, if you see some operator, everything on the left is its first operand, and single value on the right is the second operand. With this in mind, we can write Gaussian solution like this:
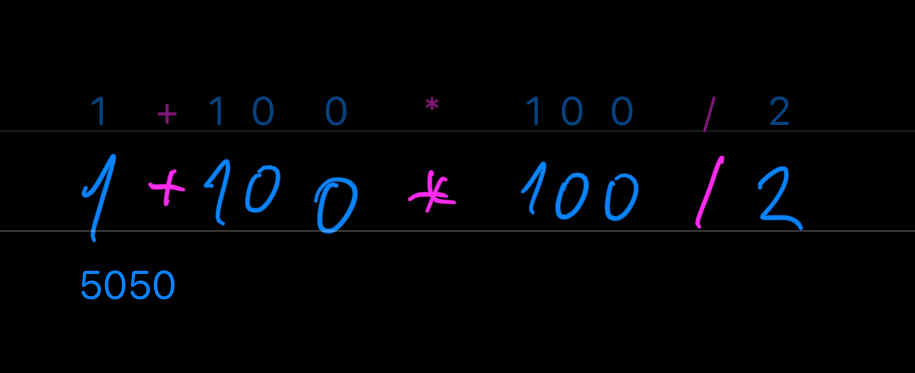
Variables
With writing these expressions, we are always repeating ourselves. Lack of abstracting things out is an inadmissible omission in a programing language. Abstraction is also a tool of thought, because we can hide unimportant details and focus on a problem we are solving. As Fluent dictates, there has to be an operator for naming things, so there is – → (assign to).
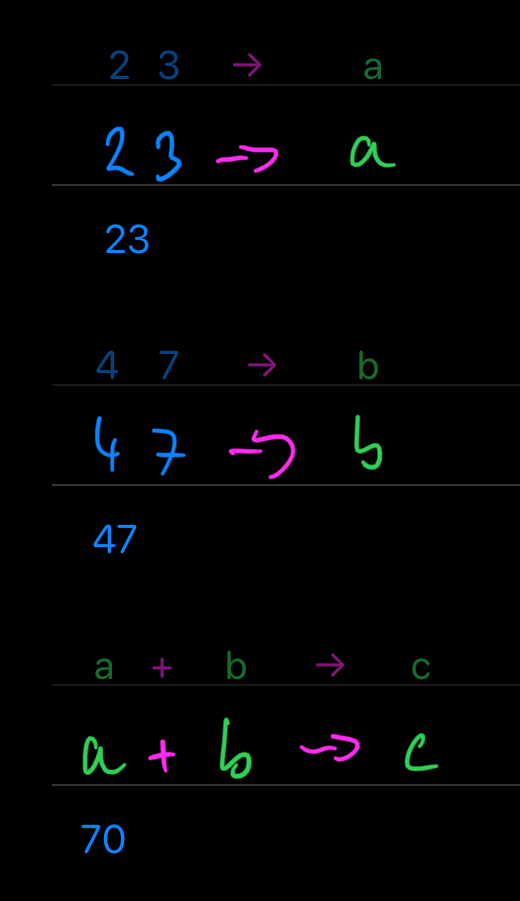
Ew, right? Even though the pipeline feels quite natural for the order of evaluation, assigning the result after the pipeline feels a bit strange. The main objection is that we want to name things before we are going to define them. A kind of description of what we would like to get at the end of the expression. I get this, but hear me out.
Naming things is hard. Correctly naming things that do not exist yet, is way harder. It is often necessary to change the name from our aim to the actual reality. This pre-name & post-name dance is something I am not sure we need. I'll be using →, and in case you like to dance, there is ← (is), but mind the required parens ().
Okay. If you haven't thrown up in your mouth a little bit yet, now you will. These are valid Fluent expressions:
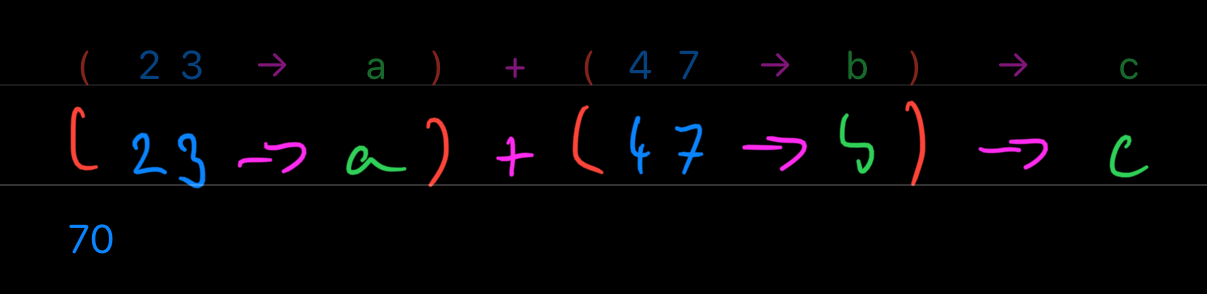
Yeah, did I mention the variables can be only single letter? Look, here is the last thing but with ←:
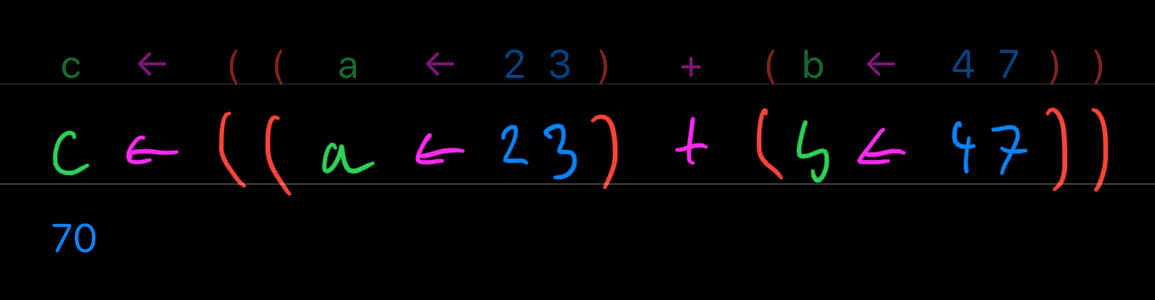
Okay, let's move on.
Our lazy and Gaussian solutions can be tested with different values for a and b like this:

Hey, look, we caught our first bug! By keeping our lazy solution around, we were able to check if we arrived at the correct formula for the Gaussian solution. Neat.
And as a last step, we need to extract the essence of the problem into a self-contained little package, so next time when the teacher asks you to add up numbers from 23 to 470, you just write 23 g 470 and you are done.
Lambdas
Fluent can be extended with custom operators. Operators are nothing more than a variable containing an anonymous function, enclosed with {}. We can create an operator for our Gaussian solution g like this:
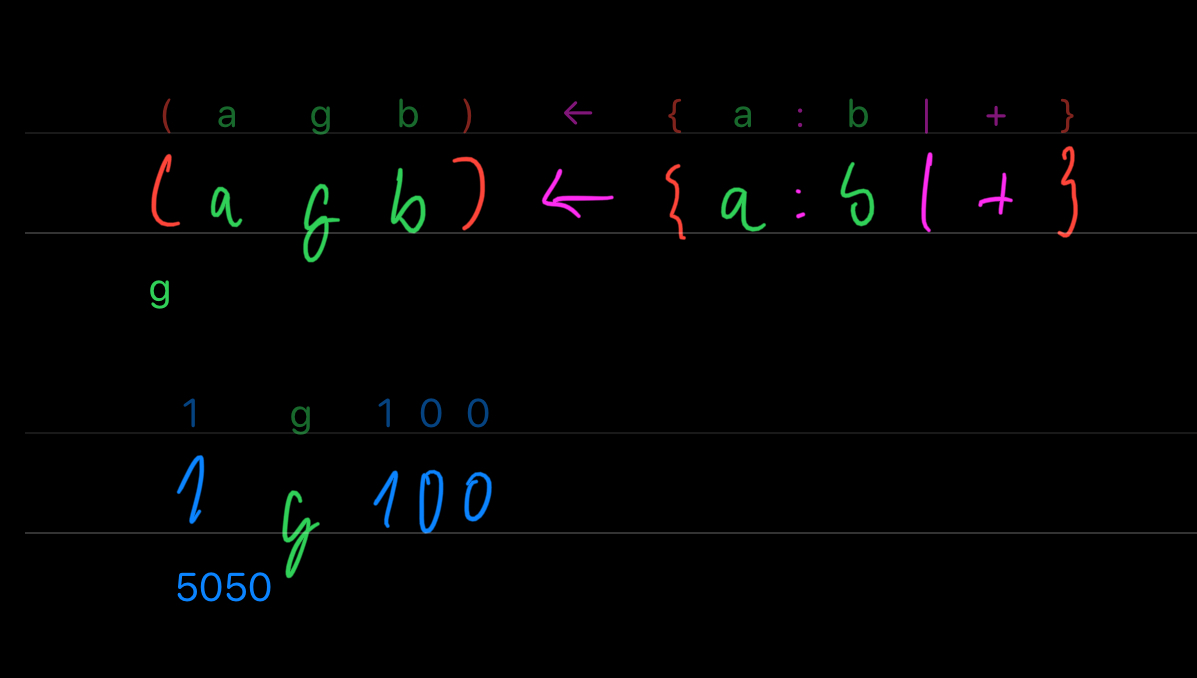
Current Challenges
Now you saw all there is to Fluent. Or to be more precise, that is all machinery you can use to combine existing operators together. There aren't many operators at the moment, and they are not really thought out, but I think this is a good direction for further exploration. Some important problems that need to be solved are:
- notation for defining overloaded operators, i.e. ad hoc polymorphism (I have some thoughts about this)
- how to call an operation with a single operand (I have some thoughts about this too)
- more useful operators
- backend to run on GPUs
While I am researching many different programming languages and paradigms, a huge inspiration comes from J, BQN, Dyalog APL and ⌽'APL'.
Pizza Box Code Sketchbook
You can solve some hard problems on the back of a napkin. However, there are much harder problems, so we will need something bigger. And way smarter! There are a lot of empty pizza boxes lying around, waiting for your ideas. Unfortunately, pizza box doesn't understand any code you'll write on it. Or maybe, just maybe, it does understand, and is silently judging you on the choice of the programming language.
Writing code by hand is very much overdue for a serious innovation. Using computerized pen and paper opens up a whole bunch of interactions that are not possible with analogue version of our thinking tools. For example, the ink doesn't have to be stuck to the place it has been written:
Also, the textual representation of the computed result is not enough. It is a classic "one thing at the time" mode which limits the thoughts we can have. Tensors can get huge in shape and rank, so there has to be a way of inspecting them in a more visual fashion, while providing useful scalar stats about them. Lucky us, 1-, 2-, 3-, and even 4-rank tensors can be easily visualized as images or videos:
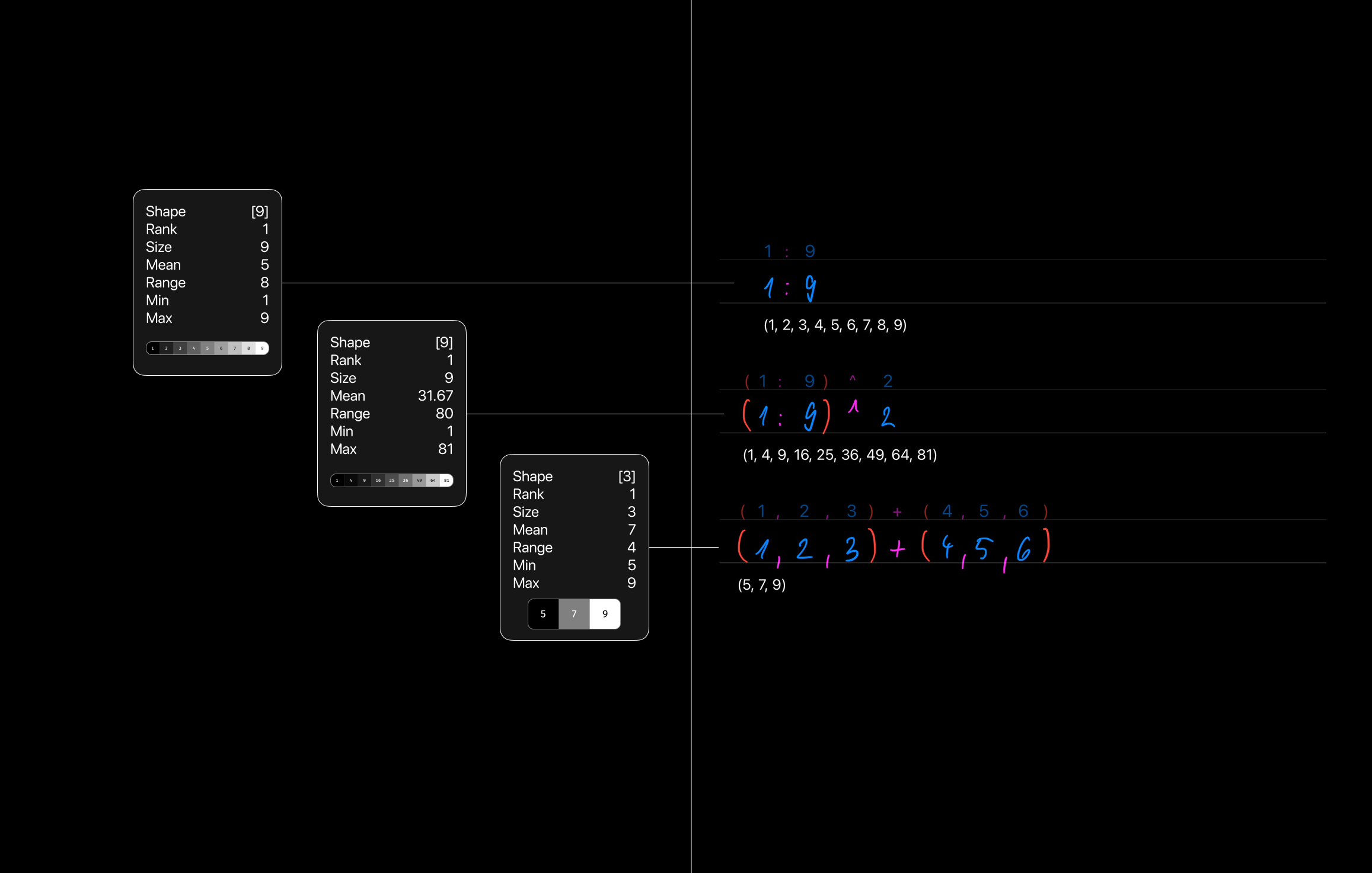
What I see as an absolute must-have feature of the new kind of paper, is the differentiability built into the language, also known as differentiable programming. I cannot yet comprehend what implications it will have on the traditional problem solving strategies, but you can get a glimpse of what kind of mind-blowing things you can do with differentiability in Julia today. Fun times ahead.

If you are still here, thank you for your time. If you found a mistake, or you have opinions about this kind of stuff, please drop me an email. Or you can stop by for a discussion on Hacker News or Reddit. I'd like to hear your thoughts, debate criticism, or just learn new stuff.
And don't forget to like and subscribe!
Ah shit, wrong medium...
Continue to New Kind of Paper, Part Three…
Changed two instances of "retarded" to more appropriate wording. Thank you to u/brandonchinn178 for pointing that out.
As u/acwaters pointed out, that tetration is
2^(2^(2^(2^2))), which is2^65536(and not(((2^2)^2)^2)^2). Exponantiation^is right-associative in crazy PEMDAS world, so we will need right reduce operator. Since I am dumb, I chose visually symmetrical glyph for reduce|, so that has to be revisited. Since Fluent supports ad hoc polymorphism, we could use\for reduce (foldl), and/for reduce right (foldr), while/can still be used as divide for tensors. Btw, right paren)in Fluent is optional, so2^(2^(2^(2^2)))can be shortened to2^(2^(2^(2^2.Removed video of Barbara Liskov from the end – it felt disconnected from the flow of the article. You can still watch it on YouTube: Barbara Liskov on the Future of Computer Science
Added PyTorch and TensorFlow references about tensors. u/jefuf didn't know.
Rewrote intro to be more punchy. A lot of rewritten parts to better explain ideas. Overall, lot of polish based on the feedback.
Removed remark about past design for custom operators –
g←{Ⓛ:Ⓡ|+}–ⓁandⓇdesignated left and right argument for the operator. This notation had several problems:- it doesn't contain information needed for polymorphic operators,
- abstracting formula into an operator requires rewriting argument names,
- it uses a bit unfamiliar glyphs
(N g N)←{Ⓛ:Ⓡ|+}, whereNdesignates a tensor type. Glyphs for other types are:λlambda,·null/undefined,@symbol,🛑error.Rewrote the pizza box code sketchbook part to contrast it with back of a napkin/envelope math, and included a link to some good discussion on why quick, iterative and collaborative problem solving is a great tool for doing impossible stuff.
Added image showing pipeline/fluent interface.
Rewrote the intro and Gauss stuff.
Made Fluent code examples in text syntax highlighted & made image code examples follow dark/light appearance settings. (Not mockups though.) And removed "light version" punchline as it does not make sense anymore.